The Memory That Makes AI Agents Truly Intelligent: A Deep Dive into AI Agent Memory
Why This Matters
Imagine hiring the world's most brilliant assistant - someone who can write code, answer complex questions, plan your day, and solve hard problems - but every morning they walk in having forgotten everything: your name, your preferences, your past projects, every conversation you've ever had.
That's what an AI agent without memory looks like.
LLMs are, by design, stateless. Every call to the model is a fresh start. It doesn't remember your name, your last conversation, or the architecture decisions you made together last week. AI Agent Memory is the engineering layer we build around the LLM to give it the feeling of continuity - the agent remembers on the LLM's behalf.
This post dives deep into what AI Agent Memory really is, the types that exist, when to use each, how it flows at runtime, real-world use cases, and the best practices that separate toy demos from production-grade intelligent agents.
The Core Problem: Statelessness
An LLM processes a prompt and returns a response. Full stop. It has no internal state that persists between calls. This creates four fundamental problems for any real-world AI agent: 47Billion
- No continuity - the next session starts from zero, nothing carried over
- No personalization - every user is treated identically
- No learning - the same mistakes repeat because outcomes aren't remembered
- No long-horizon tasks - multi-step work spanning hours or days collapses mid-way
Memory solves all four. Think of the LLM as the brain that reasons, and Agent Memory as the nervous system and diary that gives it a persistent sense of self across time.
A bigger context window is useful, but it is not the same thing as memory. Memory is the system that decides what to remember, what to retrieve, what to update, and what to forget.
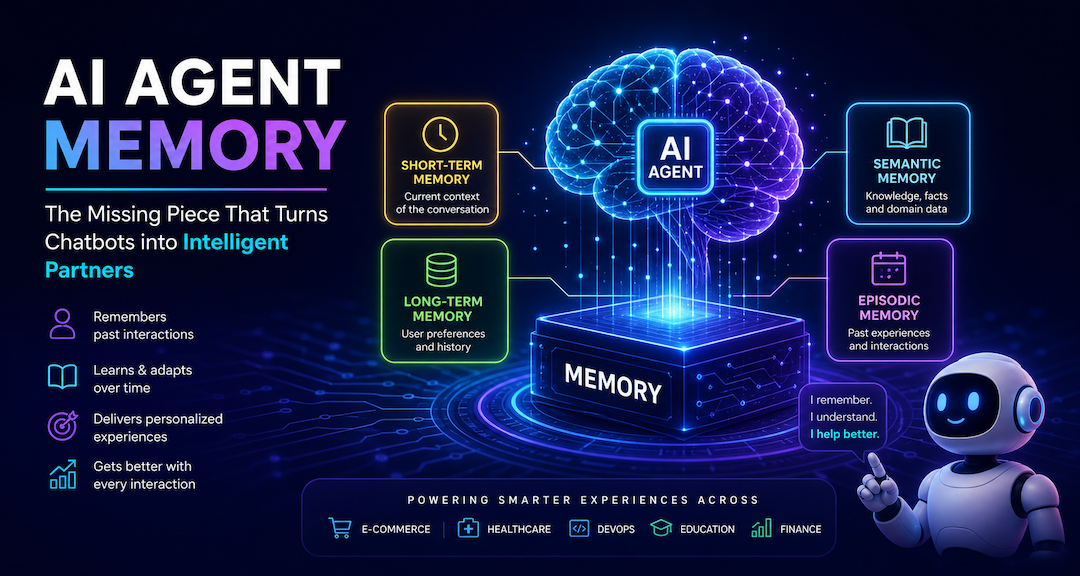
The Memory Stack: Four Layers Every Agent Needs
AI Agent Memory is not a single database or a single concept. It is a stack of layers, each with a different lifespan and a different purpose:
In the prompt. Active during a single LLM call. Lost when context overflows.
Session scratchpad and current task state. Lost when the session ends.
User facts, preferences, and past summaries. Survives across sessions.
Documents, databases, APIs, and RAG sources. Queried, not maintained by the agent.
A useful mental model: the context window is the LLM's desk, short-term memory is the notepad next to it, long-term memory is the personal diary in the drawer, and external knowledge is the library across the street. You want the desk clean, the notepad organized, the diary trustworthy, and the library indexed.
The Four Types of Long-Term Memory
Within long-term memory, there are four distinct cognitive subtypes - borrowing from human cognitive science.
| Memory Type | What It Stores | Real-World Analogy | Example |
|---|---|---|---|
| Semantic Memory | Facts, domain knowledge, user preferences | Encyclopedia | "User prefers Python over Java" |
| Episodic Memory | Specific past events and interaction outcomes | Personal diary | "Last time user asked about auth, JWT worked best" |
| Procedural Memory | Behavioral rules, protocols, how-to knowledge | Muscle memory | System prompt instructions, agent behavioral guidelines |
| Working Memory | Active context in the current session | Whiteboard | Current plan, intermediate steps, tool outputs |
Semantic memory is the most commonly implemented - it stores stable facts. Episodic memory is arguably the most powerful - it lets the agent say "here's what worked last time in a similar situation". Procedural memory encodes the how, often baked into system prompts or fine-tuned behavior. Working memory (the context window) is the battlefield where all reasoning actually happens.
The Four Core Memory Operations
No matter how many layers your system has, all memory does only four things:
1. Write
Save new information when something important occurs.
2. Read
Retrieve relevant context before the LLM sees the prompt.
3. Update
Modify existing memories when new information contradicts old.
4. Forget
Remove stale, wrong, or no-longer-relevant information.
Break any one of these, and the entire memory system breaks. An agent that writes but never reads wastes disk. One that reads but never updates acts on outdated facts. One that never forgets drowns in its own history.
How Memory Flows at Runtime
Here is what happens on every single user turn inside a memory-enabled agent:
Read -> Build Prompt -> Respond -> Write. Forever. From the user's perspective, the agent simply remembers - the entire machinery is invisible.
Example in Action
Turn 1: "My name is Priya and I code in Go."
-> Agent writes to long-term memory: {name: "Priya", preferred_language: "Go"}
Turn 2 (one week later): "Help me write a function to reverse a string."
-> Agent retrieves: "User is Priya, prefers Go"
-> LLM receives context and responds with a Go function, addressed to Priya
The LLM remembered nothing. The agent did all the work.
When to Use Which Memory Type
Not every use case needs every layer. Here's a practical decision guide.
| Use Case | Memory Type(s) Needed |
|---|---|
| Customer support chatbot (single session) | Working Memory + Short-Term |
| Coding assistant across projects | Semantic + Episodic Long-Term |
| Personal AI assistant | All four types |
| Document Q&A bot | External Knowledge (RAG) |
| Multi-agent enterprise workflows | Episodic + Semantic + Procedural |
| Recommendation engine | Semantic Long-Term |
Start simple. If your agent handles single-session tasks like a support ticket or a one-off code review, working memory (context window) is enough. Add long-term persistence only when continuity across sessions genuinely improves the user experience.
What to Store (and What Not To)
One of the most common mistakes is storing too much. Memory is valuable only if retrieval works well - and retrieval quality degrades as noise increases.
Store This
- Stable user facts (name, role, timezone, language preference)
- Strong behavioral preferences ("prefers concise answers", "always wants code examples")
- Outcomes of past tasks (what worked, what failed, what was chosen)
- Decisions that shape future work (architecture patterns, technology stack choices)
Don't Store This
- Every single message - the context window already has the live conversation
- Low-signal chit-chat ("hi", "thanks", "got it")
- Temporary state that belongs in short-term memory
- Sensitive data without explicit user consent
Rule of thumb: Store what will matter next week. Skip what only matters for the next minute.
Real-World Use Cases
1. Enterprise AI Assistant (Architecture Context)
An enterprise architect uses an AI agent to design systems. Without memory, every session restarts from scratch - re-explaining the tech stack, team constraints, and past decisions. With semantic + episodic memory, the agent knows the company uses AWS, prefers microservices, and that the last authentication proposal was rejected in favor of OAuth2. Every new session builds on the last.
2. Personalized E-Commerce Agent
A shopping assistant that remembers size preferences, past purchases, budget range, and brand loyalty. Semantic memory stores preferences; episodic memory recalls "last time we recommended Brand X running shoes, the user returned them." The next recommendation is smarter.
3. Healthcare Triage Bot
A patient-facing agent that remembers medical history, current medications, and previous symptom reports across visits. Here, long-term semantic memory combined with strict privacy controls (user-scoped, encrypted) is critical. The agent can flag drug interactions it remembers from three months ago.
4. Multi-Agent Software Development Pipeline
In a CrewAI or LangGraph multi-agent system, a planner agent stores task breakdowns in shared episodic memory, a coder agent reads those plans, and a reviewer agent writes code quality outcomes back. Agents collaborate across time without repeating work.
5. AI Coding Co-pilot
A developer's daily driver that knows they write in TypeScript, prefer functional patterns, use Jest for testing, and that a particular API integration previously caused issues. Procedural + semantic memory makes it feel like a senior teammate who actually knows your codebase.
The Technology Behind It: How Memory Is Implemented
Memory architecture in production relies on several technologies working in concert.
- Vector Databases (Pinecone, Weaviate, pgvector) - for semantic search over past memories using embeddings; best for "find me what's relevant to this query"
- Relational/Document Databases (PostgreSQL, MongoDB) - for structured user facts, preferences, and configurations
- Graph Databases (Neo4j) - for relationship-aware memory, useful when entities and their connections matter (e.g., "User A works with Team B on Project C")
- In-Memory Caches (Redis) - for short-term session state with fast read/write
- Managed Memory Layers (Mem0, AWS AgentCore Memory, Letta/MemGPT) - purpose-built agent memory systems that handle write/read/update/forget automatically
A useful mental model from the MemGPT/Letta research: treat the context window as RAM and external storage as disk, and give the agent explicit mechanisms to page information in and out on demand. This shifts memory management from a static pipeline decision to a dynamic, agent-controlled operation.
Security and Privacy: The Overlooked Dimension
AI Agent Memory introduces a new attack surface that's easy to underestimate.
- Memory Poisoning Attacks (e.g., MINJA, AgentPoison): malicious inputs that intentionally corrupt what the agent stores, causing future misbehavior
- Cross-user Memory Leaks: when memory is not scoped by user ID, one user's data surfaces in another's session
- Shared Memory Risks in Multi-Agent Systems: agents sharing a global memory store can inadvertently propagate bad data across the system
Microsoft's updated SDL for AI (February 2026) specifically calls out AI memory protections, agent identity, and RBAC enforcement for multi-agent environments. AWS prescriptive guidance recommends memory isolation policies and real-time anomaly detection for agentic memory operations.
Security Principles
- Scope every memory write to a
user_id- never mix memories across users - Encrypt memories at rest and in transit for any sensitive data
- Require explicit user consent before persisting personal information
- Implement RBAC for shared memory in multi-agent architectures
- Log and audit memory reads/writes for observability
Best Practices: Production-Grade Memory Systems
Drawing from real-world implementations and 2026 research: 47Billion
- Design memory as a systems problem, not a context-window problem. A bigger context window is not a substitute for proper memory architecture.
- Use semantic search, not keyword matching. Embedding-based retrieval finds relevant memories even when exact words differ. Store memories with descriptive titles and summaries.
- Retrieve more, inject less. Pull 10 candidates, filter down to the 3 most relevant before injecting into the prompt. Post-retrieval filtering significantly improves output quality.
- Always implement a Forget policy. Delete memories unused for a defined period. Superseded memories should be replaced, not appended to. Without forgetting, retrieval quality degrades over time.
- Write long-term memory asynchronously. Don't make the user wait while you persist memories. Write after the response is sent.
- Check for contradictions on every write. Before storing a new fact, query for existing conflicting memories. Update or replace - don't blindly append.
- Build retrieval unit tests before end-to-end tests. Create a curated set of queries paired with the memories they should retrieve. This isolates memory bugs from reasoning bugs.
- Monitor silently failing memory. Most memory failures don't crash the agent - they cause subtly wrong answers. Add logging, monitoring, and regular memory store audits.
- Start with short-term, promote to long-term deliberately. When in doubt about what layer to write to, default to short-term. Promote to long-term only when you're confident it has future value.
- Respect the user's right to forget. Implement memory deletion APIs. Users should be able to see, edit, and erase what the agent remembers about them.
Common Failure Modes (and Fixes)
| Failure | Symptom | Fix |
|---|---|---|
| Context window overflow | Agent loses critical earlier context | Summarize old turns; inject only top-k relevant memories |
| Retrieval miss | Agent has the memory but doesn't use it | Use semantic embeddings; improve memory titling |
| Outdated memories | Agent acts on stale facts | Implement contradiction-check on every write |
| Memory bloat | Retrieval becomes slow and noisy | Add TTL-based forget policies |
| Privacy leak | User A's data surfaces for User B | Scope all memory by user_id; never mix |
| Layer confusion | Ephemeral state pollutes long-term store | Be explicit about which layer each write targets |
The 2026 Landscape: Where Memory Is Heading
The state of AI agent memory has matured significantly.
- Managed memory-as-a-service platforms like Mem0 and AWS AgentCore Memory are abstracting away the infrastructure complexity, letting developers focus on what to remember rather than how.
- Graph memory is gaining traction for use cases requiring rich entity relationships - particularly in enterprise knowledge management.
- Memory evaluation benchmarks like LongMemEval and LoCoMo are emerging to rigorously test multi-session retention.
- Agentic memory security is becoming a first-class engineering concern, not an afterthought.
The trajectory is clear: memory is moving from a nice-to-have feature to the foundational infrastructure layer of any serious AI agent system.
The Takeaway
An LLM without memory is a brilliant mind with amnesia - capable of extraordinary reasoning in the moment, but unable to build lasting relationships, learn from experience, or handle work that spans days and sessions.
AI Agent Memory is what transforms an LLM from a clever but forgetful tool into an intelligent agent that truly knows you, grows with you, and gets better over time.
The four-layer memory stack, the CRUD-like operations (Write, Read, Update, Forget), the cognitive memory types (semantic, episodic, procedural, working) - these aren't just academic concepts. They're the engineering primitives that determine whether your AI agent feels like a novelty demo or an indispensable colleague.
If you're building agents today - whether with CrewAI, LangGraph, LlamaIndex, or custom architectures - memory is where the experience lives. Get it right, and users will say the agent "just gets them." Get it wrong, and it'll feel like starting over every single time.
Share this article



Recent Posts
End-to-End Agentic AI Strategy
A complete enterprise strategy for driving autonomous execution, process transformation, governed scale, Zero Trust agent identity, human oversight, and measurable ROI from Agentic AI.
Beyond the Dashboard: How Meta's New MCP Server is Ushering in the Age of Agentic Advertising
Meta Ads AI Connectors mark a shift from dashboard-driven media buying to autonomous agentic advertising, changing how teams monitor, optimize, and govern campaigns.

The AI That Could Hack the World: How Anthropic's Claude Mythos Is Rewriting Cybersecurity
Anthropic's Claude Mythos Preview has unearthed 27-year-old vulnerabilities and can chain Linux kernel exploits. This unreleased AI is forcing a massive cybersecurity reckoning and stock market whiplash.

TurboQuant: How Google Just Rewrote the Rules of AI Efficiency
A smarter way to compress AI's most precious resource — without losing a drop of intelligence. Here's why it matters for everyone from engineers to everyday users.

Architecting the Agentic Enterprise
These 10 reusable agentic AI blueprints show how autonomous systems can plan, act, reflect, retrieve, collaborate, and stay aligned with human judgment for real enterprise advantage.
The Agentic Shift: Moving from Chatbots to Digital Coworkers
By 2026, enterprises are moving from AI chatbots that answer questions to digital coworkers that own outcomes across end-to-end workflows.

The Future of Agentic AI in Enterprise Applications
Why the next 3–6 months will define enterprise AI leadership — and how product and technology leaders can prepare for agentic systems that plan, decide, orchestrate, and execute.